Watcher
The watcher is implemented as a pyinotify daemon that is controlled via the manage.py. If you are more interested about how this module works, it uses inotify that comes from the linux Kernel. It’s basic function is going to be doing stuff when the filesystem is changed in the location(s) we specify, in the way that we specify.
Basic Workflow
The basic workflow of the watcher is the following:
- The user starts the daemon.
- The process id is stored at
watcher.pidin the application base folder at/code/sendit. Generally, we always check for this file first to stop a running process, stop an old process, or write a new pid. A clean exit will remove an old pid file. - Logs for error (watcher.err) and output (watcher.out) are written under logs. We likely (might?) want to clear / update these every so often, in case they get really big. The logging itself is done with the sendit/logger.
- The daemon responds to all events within the
/datafolder of the application. When this happens, we trigger a function that:- checks for a complete series folder
- if complete, adds to database and starts processing via a celery task
Usage
Specifically, this means that you can start and stop the daemon with the following commands (from inside the Docker image):
python manage.py start_watcher
python manage.py stop_watcher
When you start, you will see something like the following:
python manage.py start_watcher
DEBUG Adding watch on /data, processed by sendit.apps.watcher.event_processors.DicomCelery
and you will notice a pid file for the watcher generated:
cat sendit/watcher.pid
142
along with the error and output logs:
ls sendit/logs
watcher.err watcher.out
and if you are looking at the web portal, it will indicate that the watcher is active:
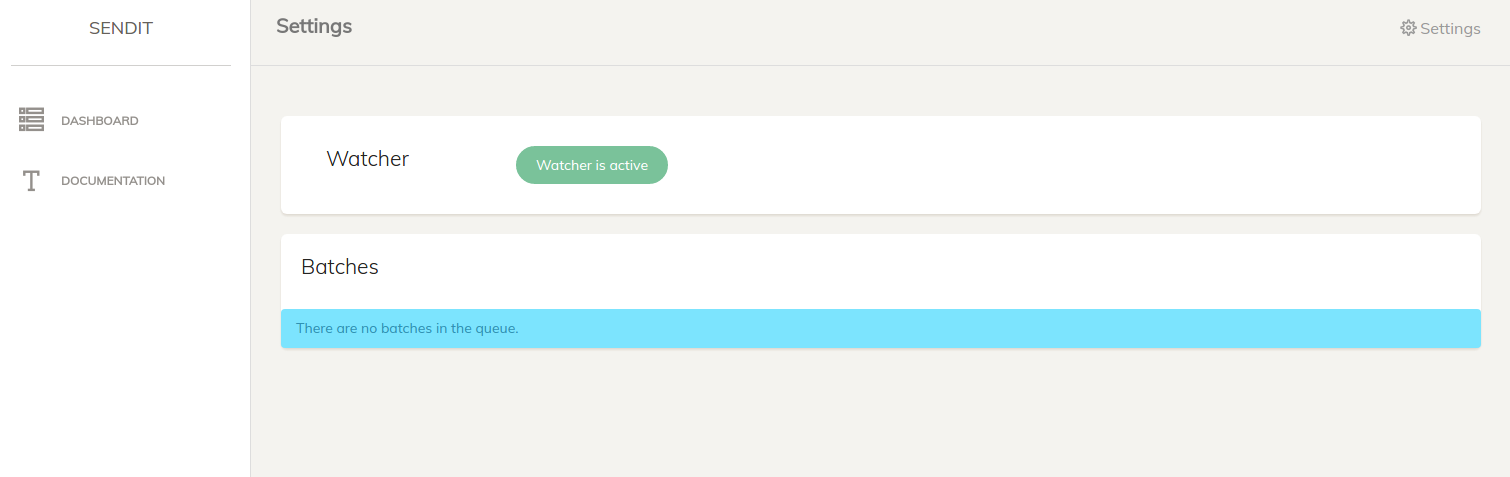
Then when you stop it, the pid file will go away (but the error and output logs remain)
python manage.py stop_watcher
DEBUG Dicom watching has been stopped.
and the watcher is inactive:

Configuration
Configuration for the watcher is stored in settings/watcher.py.
Logging
How did those files know to be generated under logs? We told them to be. Specifically, in this settings/watcher.py we define the locations for the output and error files, along with the PID file to store the daemon process ID:
BASE_DIR = os.path.abspath(os.path.join(os.path.dirname( __file__ ), '..'))
LOG_DIR = os.path.join(BASE_DIR,'logs')
INOTIFIER_DAEMON_STDOUT = os.path.join(LOG_DIR,'watcher.out')
INOTIFIER_DAEMON_STDERR = os.path.join(LOG_DIR,'watcher.err')
BASE_DIR refers to the /code/sendit directory, meaning that our logs will be found in /code/sendit/logs, and out daemon by default will be generated as a file called watcher.pid under /code/sendit. If there is, for any reason, an error with these paths, the same files will be generated in /tmp.
Watch Paths
A “watch path” setup can be thought of as one or more tuples, each including:
- an actual folder to watch
- the level of events to watch, based on pyinotify events types
- the signaler to use in our application, currently defined in watcher.event_processors
Thus, if you want to change some function, whether that be the kind of event responded to, how the response is handled, or what locations are watched, you can do that by tweaking any of the above three things. For our settings file, we use a function to return a list of tuples:
# Logging
INOTIFIER_WATCH_PATHS = generate_watch_paths()
and the function generate_watch_paths is defined as follows:
def generate_watch_paths():
'''Don't import pyinotify directly into settings
'''
import pyinotify
return (
( os.path.join('/data'),
pyinotify.ALL_EVENTS,
'sendit.apps.watcher.event_processors.DicomCelery',
),
)
Note that this example returns just one, however you could return multiple, meaning that you have three folders with different events / responses setup:
How does it work?
The functions are stored in the management/commands folder within the watcher app. This organization is standard for adding a command to manage.py, and is done by way of instantiating Django’s BaseCommand:
from django.core.management.base import (
BaseCommand,
CommandError
)
When the user starts the daemon, after doing the appropriate checks to start logging and error files, the daemon starts pyinotify to watch the folder. Each time a file event is triggered that matches the settings given to pyinotify, the event is sent to the function specified (the third argument in the tuple) defined in event_processors. If you are curious, an event looks like this:
event.__dict__
{
'name': 'hello',
'maskname': 'IN_CLOSE_NOWRITE|IN_ISDIR',
'wd': 1,
'dir': True,
'path': '/data',
'pathname': '/data/hello',
'mask': 1073741840}
}
It is then up to the function in event_processors to decide, based on the event. For example, if you use the AllEventsSignaler class, a proper signal defined in signals.py will be fired (this is not currently in use, but could be useful if needed). It would look something like this for something like accessing a file:
# In event_processors.py
class AllEventsSignaler(pyinotify.ProcessEvent):
'''Example class to signal on every event.
'''
def process_IN_ACCESS(self, event):
signals.in_access.send(sender=self, event=event)
# in signals.py
import django.dispatch
in_access = django.dispatch.Signal(providing_args=["event"])
For our purposes, since we already have an asyncronous celery queue, what we really want is to write to the log of the watcher, and fire off a celery job to add the dicom folder to the database, but only if it’s finished. As a reminder, “finished” means it is a directly that does NOT have an extension starting with .tmp. For this, we use the DicomCelery class under event_processors that fires off the import_dicomdir async celery task under main/tasks.py instead.
For better understanding, you can look at the code itself, for each of start_watcher.py and stop_watcher.py.
Testing
I made a testing mode so it’s easy to shell into the Docker image and get a feel for starting, and using the watcher specifically for a DICOM directory. It will work by starting the watcher, but generating a directory in the /data folder that begins with any derivation of test. First we will start the watcher, and created a test directory that is “finished” because it doesn’t start with a ‘.tmp*’ extension:
root@0b0b9c4f2a6e:/code# python manage.py watcher_start
DEBUG Adding watch on /data, processed by sendit.apps.watcher.event_processors.DicomCelery
root@0b0b9c4f2a6e:/code# mkdir /data/test_finished
we can now look in the watcher’s output log to see that it identified the finished directory:
root@0b0b9c4f2a6e:/code# cat sendit/logs/watcher.out
LOG 1|CREATE EVENT: /data/test_finished
LOG 2|FINISHED: /data/test_finished
The watcher will log the event type (the first line with 1| always followed by if the event indicates the dicom directory being finished (the second line with 2|). This first example is finished because there is no *.tmp extension. Now we can create an unfinished directory, indicated by having an extension .tmp*:
root@0b0b9c4f2a6e:/code# mkdir data/test_notfinished.tmp1234
and we can again look at the output file to see that an addition has been made to indicate the creation of the directory:
root@0b0b9c4f2a6e:/code# cat sendit/logs/watcher.out
LOG 1|CREATE EVENT: /data/test_finished
LOG 2|FINISHED: /data/test_finished
LOG 1|CREATE EVENT: /data/test_notfinished.tmp1234
LOG 2|NOTFINISHED: /data/test_notfinished.tmp1234
In the example above, only a directory that is flagged as FINISHED in step 2| would start through processing. A directory that is FINISHED and changed will have the series already found in the database, and will not be processed again.
Let’s now mimic the action of “finishing” a directory. In the example above, we would have created the /data/test_notfinished.tmp1234 before adding dicoms, and then when we are finished we would want to rename it to it’s final form, to be detected by the watcher as finished. Likely a script would be doing this for us as the dicoms come in. We can do that now manually:
mv /data/test_notfinished.tmp1234 /data/test_nowfinished
and then verify that the watcher detects the change, and marks the directory as finished:
LOG 1|CREATE EVENT: /data/test_finished
LOG 2|FINISHED: /data/test_finished
LOG 1|CREATE EVENT: /data/test_notfinished.tmp1234
LOG 2|NOTFINISHED: /data/test_notfinished.tmp1234
LOG 1|MOVEDTO EVENT: /data/test_nowfinished
LOG 2|FINISHED: /data/test_nowfinished
and at this point, if we weren’t testing, processing of the dicom directory would happen. For this example, we can now stop the watcher.
root@0b0b9c4f2a6e:/code# python manage.py stop_watcher
DEBUG Dicom watching has been stopped.
root@0b0b9c4f2a6e:/code#
Note that the sendit/watcher.pid file will be removed after you stop it. If you were to try and stop it again (when it’s already stopped) it would tell you that it isn’t started:
root@0b0b9c4f2a6e:/code# python manage.py stop_watcher
CommandError: No pid file exists at /code/sendit/watcher.pid.